Auto-Setup Wizard
The Auto-Setup Wizard is the fastest way to initialize a robust, AgentCommander-compatible experiment environment.
Using the UI Wizard (Recommended)
The easiest way to start is using the built-in Experiment Setup wizard directly in the web UI.
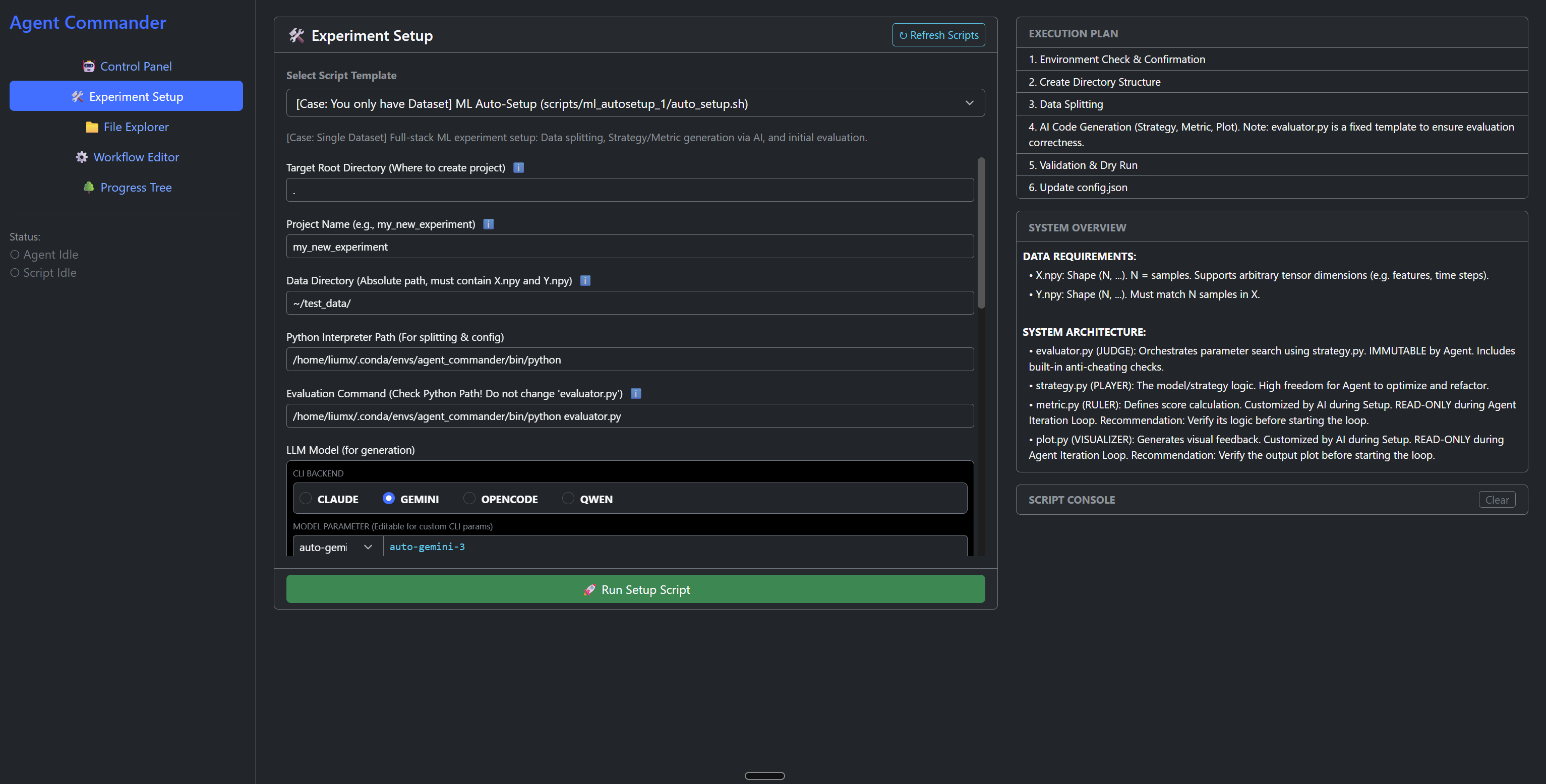
- Navigate to "Setup": Click the "Experiment Setup" tab in the UI sidebar.
- Select a Template:
[Case: You only have Dataset]: Corresponds to Scenario 1 below.[Case: You have Training Code]: Corresponds to Scenario 2 below.
- Configure: Fill in the required fields (e.g., Project Name, Absolute Path to Data).
- Launch: Click 🚀 Run Setup Script.
- The integrated console will show the setup progress as it creates directories, splits data, and generates the initial
evaluator.py.
- The integrated console will show the setup progress as it creates directories, splits data, and generates the initial
Scenario 1: Data-Only (ml_autosetup_1)
Use Case: You have a dataset (X.npy, Y.npy) but no model code. You want the Agent to build a model from scratch.
Workflow
- Input: Path to your data directory.
- Splitting: The script runs
split_data.pyto createX_train.npy,X_test.npy, etc. - Generation: The Agent generates an initial
strategy.pyandmetric.pybased on your description. - Verification: Runs a dry run to ensure the generated code runs.
Scenario 2: Bring Your Own Code (ml_autosetup_2)
Use Case: You already have a training script (strategy.py) and want the Agent to optimize hyperparameters or architecture.
Requirements (The BYOC Protocol)
To use this mode, your code must adhere to a simple interface contract so the Evaluator can judge it:
- Weight Saving: Your script must save the best model weights to a file (e.g.,
best_fast.pt). - Loading Interface: You must implement a factory function:
- Data Protocol: Your code should load data using the shared
experiment_setup.pymodule (generated by the wizard) to ensure train/test splits are consistent between the Player (Strategy) and the Judge (Evaluator).
What it Generates
experiment_setup.py: Locks the random seed and data splits. Immutable.evaluator_ref.py: A template evaluator that loads your model and tests it against the reserved test set.
Common Features
- Metric Standardization: Both modes verify that the evaluator prints
Best metric: {val}(lowercase 'm') for the workflow to parse. - Safety Checks: Both modes include anti-cheating checks (e.g., verifying
y_testwas not modified in memory).